Considering we have a simple Datomic database, where we do 3 transactions:
First we add an app. Then we add a chat "c1" in that app. Then we add another chat "c2" in the same app.
Looking at the transaction history:
Now we can pull, at the different times of the transactions, using as-of meaning we'll only see the results as they were at that time:
But another interesting thing, is seeing the changes since a particular time using since (think you're asking only for changes since a particular time):
We have to write an endpoint which returns an offer by its id: GET /offer-by-id/:offer-id Possible results: - 200 {"offer-id":2, "offer-data":""} - 400 {"errors":["The id you provided is invalid"}]} - 404 {"errors":["The id you provided cannot be found"}]} IMPORTANT: if an id is valid but not found the deposit must be notified!
Solution 1: IFs
The problem could be solved by:
Or in code:
Whenever we have ifs in code, it becomes dificult to read so maybe we could simplify it, making it more like: step 1 then step 2 then step 3 Or more like validate then find offer then jsonify Hmm, can we?
Solution 2: Exceptions
We'll use exceptions to break out flow:
The solution above is very present in Java, even if the way the errors are caught might not be this explicit. Because it's a fairly simple example we could also use the strategy pattern. Basically we use ifs to choose a strategy, then we execute it to give us the result.
Solution 3: strategy pattern
Functional programming gives us sever possibilities using pipes. What is a pipe? A pipe makes sure that steps get executed in a certain order and that the result of a step is passed to the next step. Like:
In our case we'd like something like: validate(requestId) .then(findOfferById) .then(jsonify)
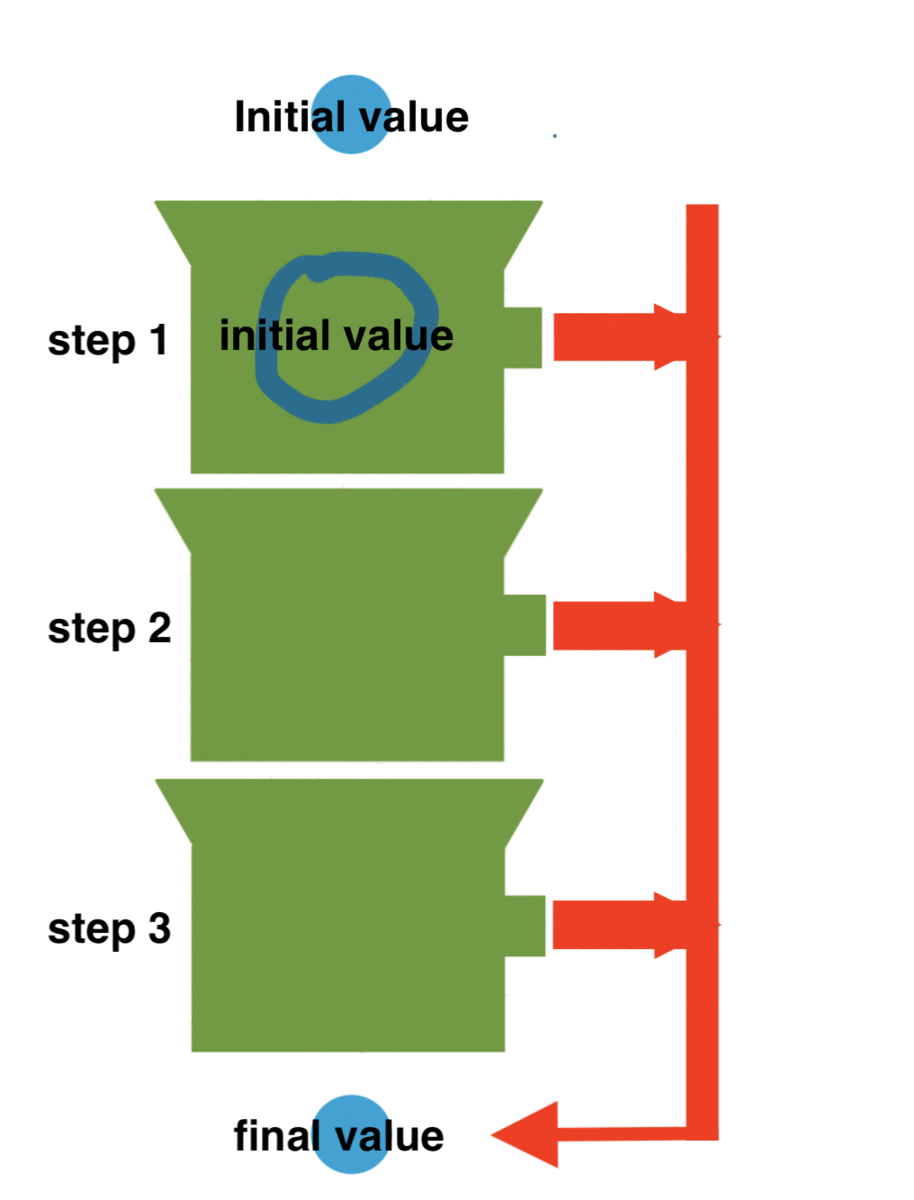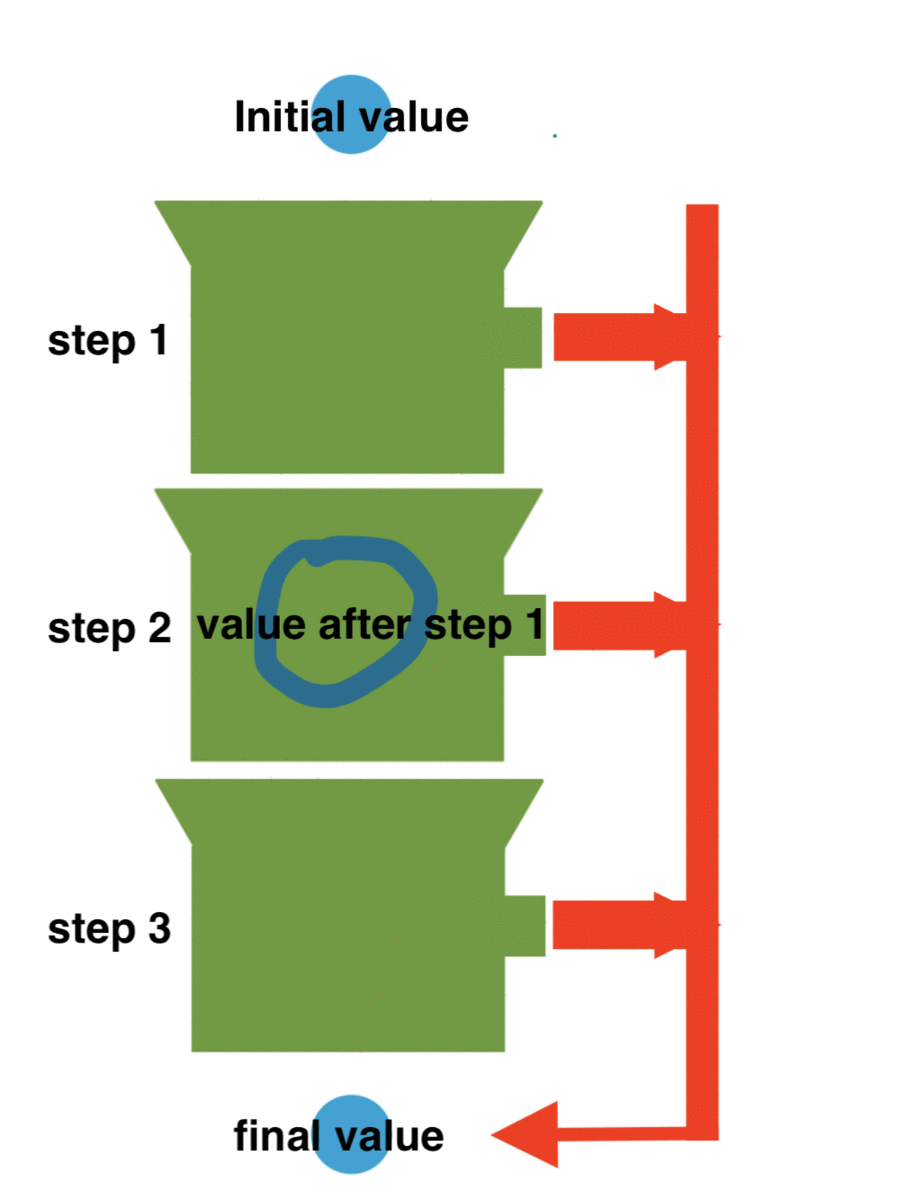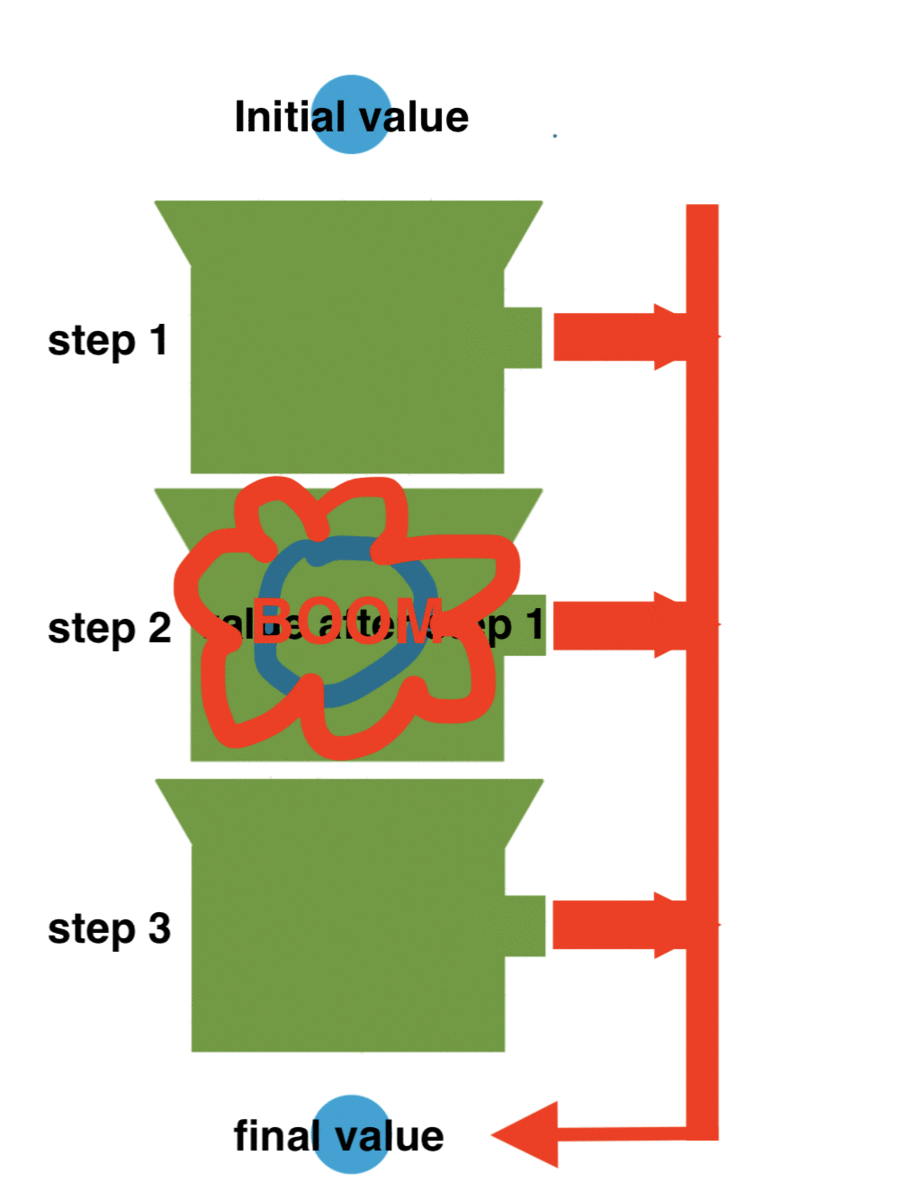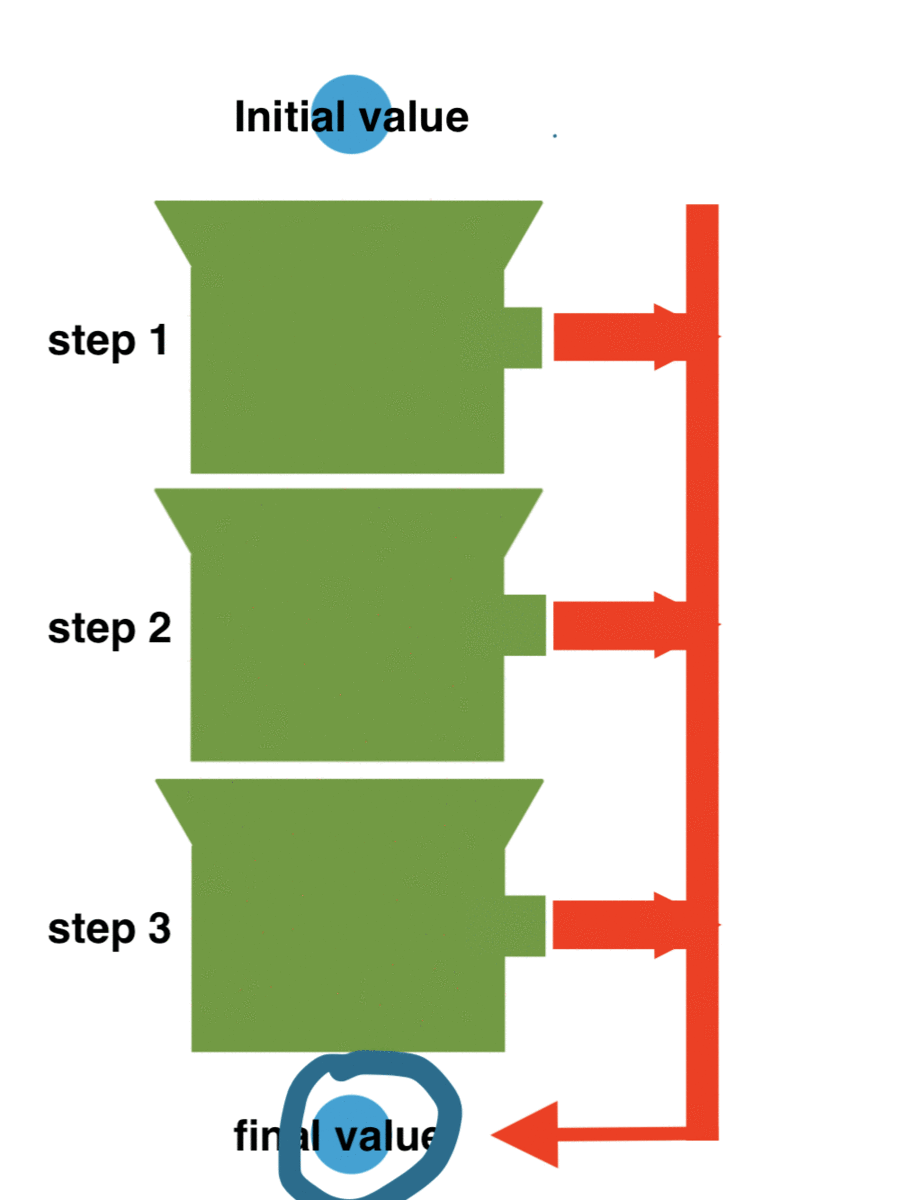
Solution 4 Functional either or railway oriented programming This is a very common solution in typed functional languages such as F# or Haskel, but it's becoming very common in Java as well. Having a single pipeline is very beautiful but how do we handle errors? By using two parallel pipes. A pipe for the happy path and a path for the errors. Basically all our functions can return either a SuccesfullResponse or a ErrorResponse. This will get passed on to the next function that will process it and return again either a SuccesfullResponse or a ErrorResponse. In F# we'd have something like: findOrderById: IResponse -> SuccesfullResponse | ErrorResponse we might describe it like: SuccesfullResponse | ErrorResponse aFunction(SuccesfullResponse | ErrorResponse response) For the happy path we'd have:
And if we get a validation error in the first step we'll have:
And the code, will have a class for Success and a class for Error. Each will inherit an IResponse and will implement two functions receiving a function (lambda) then and fail. In Succes we'll return the result of applying the function on what we have on then and the data we have on fail, and on Error we'll do exactly the opposite. Imaging you'd replace then with map and fail with orElseGet, doesn't that sound like an optional?
In dynamic languages, there are other options. But first let's describe functional composition. Functional composition is when you combine 2 (or more) functions into one, then apply it. It's pretty much like pipe but you may do the composition at runtime. Now we can look at the two options. First is:
Solution 5: pipeline with flag
We'll pass through the pipe an object that contains a flag which tells you whether there were errors before. Basically using a value in your data instead of using the type of the data (has response property instead of type: Successful or Error).
In our case, the flag is whether a response has been set already: if(state.response) return state;
Solution 6: pipeline + overflow pipeline
The second option is to have a pipeline and an overflow pipeline.
We'll use exceptions once again to bypass the normal pipeline and go to the overflow pipeline.
Unlike the previous two options when an exception happend it will jump straight to the end, bypassing the next steps directly.
In terms of readability it could be a lot easier, to see the code as a pipeline: step 1 then step 2 then step 3 While also handling the errors: step 1 then step 2 then step 3 fail on-error or safe( step 1 then step 2 then step 3 )
Extensibility
But what about extensibility?
We now have to modify our endpoint
to check if the offers are still active. If the aren't we need to return an error
to update the number of times the offer has been accessed
GET /offer-by-id/:offer-id Possible results: - 200 {"offer-id":2, "offer-data":"", "active":true, "requests":1} - 400 {"errors":["The id you provided is invalid"}]} - 400 {"errors":["The offer expired"}]} - 404 {"errors":["The id you provided cannot be found"}]}
IMPORTANT: if an id is valid but the offer expired the deposit must be notified! We changed the tests:
Then we change the code and we can look at how For solution 1:
The way we solved it was to add more ifs inside an existing if thus increasing the cyclomatic complexity of the solution making it even harder to read. And real life code tends to be more complex than this. For solution 2:
We did:
added a new exception
changed the code inside the try catch block
changed the code in the catch
For solution 4:
What did we do:
added two new functions, completely independent
modified an existing one
added steps to the pipeline
For solution 5:
What did we do:
added a new function
heavily modified an existing one
added a step to the pipeline
For solution 6:
What did we do:
added a two new functions
added them as steps to the pipeline
No existing code modified! (except for the pipeline, which is expected)
The requirements come, you have some UI mockups and now you need to start developing a web app. What is the first step you need to do?
Let's go back a bit. If this was not a specific web app, but rather generic:
What would our strategy be like?
What would be our goals?
Which steps would we have to do?
Which patterns could help us?
What tactics could we use?
In the following lines I will try to address exactly this questions. First we'll discuss the theory and then we'll develop a web app.
we'll start with a little bit of theory, then we'll put it in practice:
THEORY
Strategy
We'll have to think a bit strategically and a little bit tactically. For the strategy, what would be our goals:
Goals
Break the complexity down (state machines, separation of concerns)
Build robustness into the system (atomicity with rollback)
Ok, but how can this be done?
Well, we'll do it in 4 Steps
Finite state machine diagram (state/transitions starting from the UI)
States (domain modelling for the states)
Transitions (TDD the controller)
Presentation/UI for the states (TDD the view)
Steps don't need to be sequential, in fact it is recommended to do the last two in parallel.
Tactics
We will be using a few Patterns:
finite state machines
separation of concerns using MVC
atomicity = all or nothing
and a few Techniques:
TDD - for the non UI
TDD - for the UI
Design by contract
PRACTICE
TodoMVC web application, because everyone loves to prove their framework with it, but we'll focus on what we said before.
Step 1 Draw the diagram of the UI state machine
So let's start with Step 1 Finite state machine
Our purpose is to create a state diagram with all the states and transitions we think we'll need. This is not an easy step, but it can clarify the entire development process further on. Let's see what can be done
Actions:
list
filter
add
check/unckeck
edit
delete
From the screens it also look like we'll have the following States:
list (filtered or not)
add
edit
and now let's put it in a diagram:
or:
Now using theis diagram we'll move to step 2 and we'll do the code according to it.
Step 2: Domain modelling
We will separate the different concerns using the MVC pattern. All the logic will be in the controller, the data in the model and we'll add the presentation later or someone else could do it in parallel.
Our data will have to be able to represent all the states in the diagram above: list/filter, add and edit
Now we know how we could represent our states as data in the model, let's test drive the different transitions which will al be functions in the controller. Normally I start with a plan, where I will know what I want to test.
Any refactorings? No, let's move to the second test and so on until we solve the entire data problem, one test at a time, making sure it fails, then making it pass, then refactoring the code. We end up with this:
Complexity problem -solved by making a state machine and using separation of concerns.
Robustness problem - TDD is a clear step forward but we can go further:
add atomicity into the transitions/operations (all or nothing)
design by contract, always making sure the states are valid states
This article: https://reactjs.org/docs/thinking-in-react.html introduces people to working with React in Javascript. I thought it would be nice to have the same simple application made in Clojurescript with Reagent (which also uses React underneath)
For example
class ProductCategoryRow extends React.Component {
In the following video, you will see a graph and how in time we expand the code using the Outside-in TDD
Requirements
We have an web API where we should be able to write and read articles and their comments.
Acceptance Test
We save an article:
POST /api/1/save/Article
{
"title":"New article",
"content":"The content"
}
and we receive the article + id
{
id: 13, - can be any value
title:"New article",
content:"The content"
}
We then add 2 new comments:
POST /api/1/save/Article
{
id: 13, - can be any value
comments:[
{"comment":"This was awesome!"},
{"comment":"I loved it as well!"},
]
}
response:
{
id: 13, - can be any value
title:"New article",
content:"The content"
}
and now reading the articles and the comments:
POST api/1/query/Article
{
find: [id,title,content,{comments:[id,comment]}],
where:{id:13}
}
should return
{"13":{
id: 13, - can be any value
comments:{
"113":{"comment":"This was awesome!"},
"114":{"comment":"I loved it as well!"},
}
}
}
Outside-In TDD approach
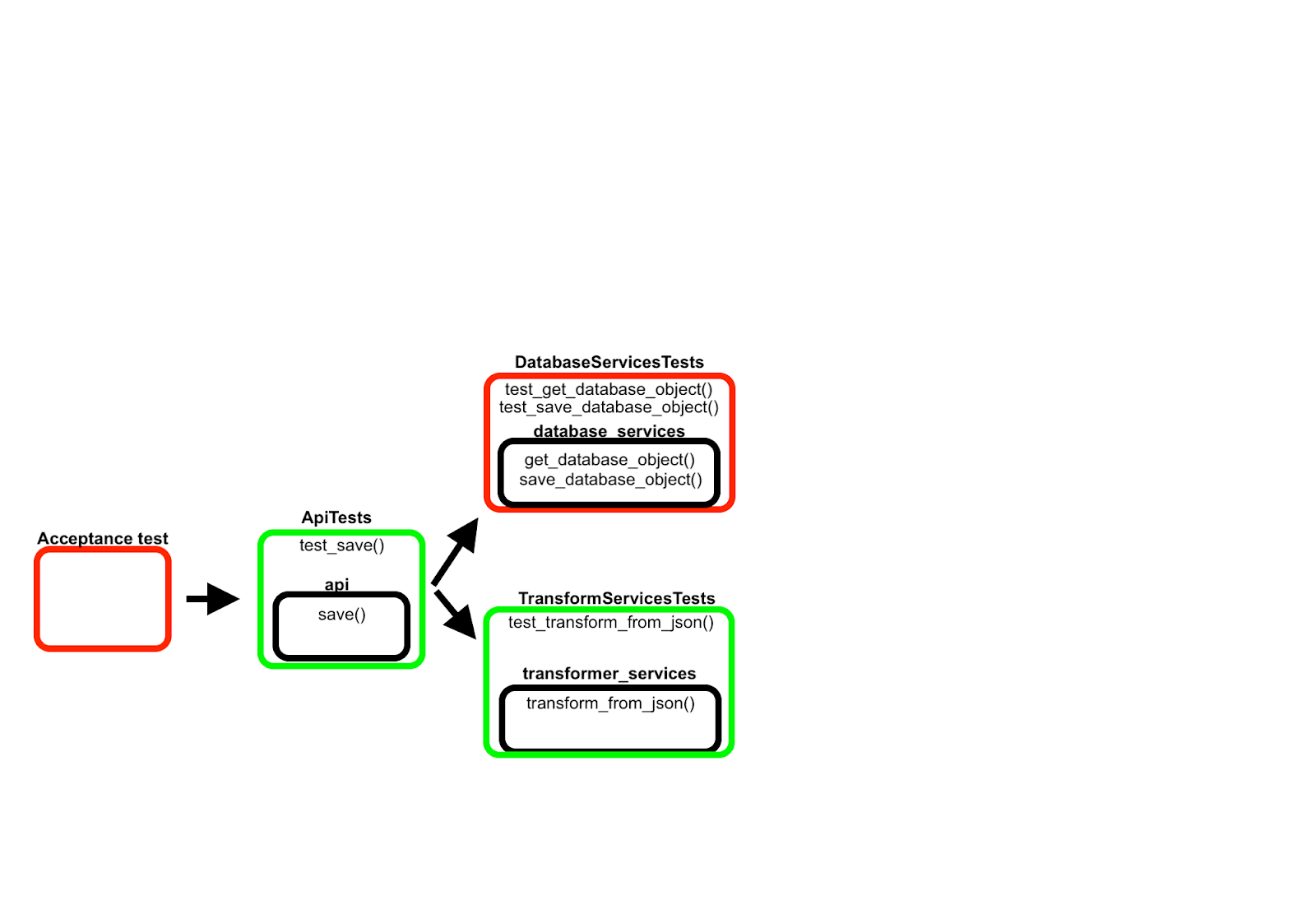
Unlike classicist TDD, in Outside-In, you start the code from the outside, designing it along the way. You start with an acceptance test, then with the unit/integration tests and code needed until you make the acceptance test work:
So let's begin:
Step 1: Acceptance test
When we run it:
2. Step 2 moving in,
From the outside, writing the first test for the service that will handle the url. A little bit of design, while writing the test: we consider, that we will use a function that will get the object from the database if we have an id in the json or will give us a brand new Article object if we have no id in the json.
Now if we properly do the code, the test will pass:
Step 3: moving furher in, database_services and get_database_object
However, we did not implement the get_database_object, which will work with the database. So for that we'll write the tests first:
or:
and
Now let's write the code to make it pass:
We write in fact 2 tests to cover both scenarios: when editing or when adding a new article.
Step 4: now we move back and extend the api
We design it to read the data from json and transfer it to the database object. For that we'll use a function transfer_from_json
Once it passes, we move further:
Step 5: writing the transfer service
Now we make the test pass:
Step 6: back to extending the api
We now need to save the object with the data from the json into the db
For this, we extend the test:
and make it pass, then we move back to implementing using TDD the save_database_object
Step 7 extending the database_service to also save
Once we write the test, the code and make it pass:
we move back to the api
Step 7 extend the api
Step 8: TDD the extension:
Until we make it pass:
After a few more intermediary steps:
...
We will TDD all the necessary code to make the acceptance test pass:



































































{kind=link}