Download as ppt
hereProblems-information too late to managers - better tracking - solving it, increases profit by not losing lots of work and redoing it
-bad quality projects - solving it increases profits, by not debugging from our own pocket
-late projects, lack of time - solving it increases customer satisfaction and guarantees future contracts
-poor communication with the customer, management (already discussed), inside team and with the code - solving it increases the speed and trust in development
Solutionsthe 3 core practices as a solution
-Iterations – projects get divided into short equal iterations, at the end of each some new functionality get shown to the client
-TDD – Test Driven Development, a design practice oriented at making development faster and changes late in development much easier
-Self improvement meetings – reflection workshops listing that activities divided as: to keep, to drop, to try
Information Too Late To Managers: Sow how can we manage?Problem:
Manager need to know the information fast and very reliable, but it is not happening until it is usually very late and hard to cope with
Causes: -the way information travels to managers is in many times flawed. Asking an engineer/programmer whether will he be ready on the planned date, is just like asking whether your new Armani suit looks good on you. In most cases the cannot tell you no, even if they are very well intentioned.
-a manager gets to see the actual software a few days before the delivery is scheduled, when in many cases is too late
-most times managers only get reports about the work, which as seen previously can be made more positive then the reality is, and if the status document travels upwards, it tends to be 'improved' by the ones that get their hands on it
Solution (Information Too Late To Managers: Sow how can we manage?)
2 managers (Ken Schwaber and Jeff Sutherland) running large companies, with lots of codebase and problems in the early 90s invented a methodology that allows them to get the REAL information ON TIME. It is called
SCRUM, and it only has very few practices:
-
Self managing, cross functional teams or max 6-8 people (for more a scrum of scrums is applied)
-
Backlog (the list of things to be done)
-
Sprints (One month iterations)
-
Sprint planning meeting (at the beginning of the sprint)
-
Product demo meeting (demo to the client at the end of the sprint)
-
Daily meetings (each morning developers say what they do, and what the problems are if any)
A process outline1. Build backlog (list of items/features etc needed in the application) and prioritize – the big plan with releases
2. Organize the first iteration/sprint, cutting from the prioritized backlog - a sprint=a project
3. Iteration/Sprint Planning meeting - detailing with the customer what needs to be done, no need for too many details before
4. Daily meetings throughout development - finding out what is going on
5. Product demo meeting - SEEING actually where the project really is
6. Go to step 1 or 2 for the second sprint
So the backlog is the plan to follow, the demo is when the manager sees if the team is on track or not. If it is not they can be fired, replaced etc instead of actually seeing the problems after 5 months on a 6 months project, when it is impossible to do something. In the daily meeting the manager can find out what are the problems in the team, especially if they are going to be late with the sprint delivery.
Process sample: building the backlog/list of requirementsA new client who wants a new software product to manage and track his sales and customers. System to go live in 2 months. We meet and establish what is required, then plan to meet the deadline. After the first meetings we come up with the following feature list, that he thinks he wants, that is afterwards estimated by us:
Client management (3p)
Product management (3p)
Sales leads management (4p)
Sales reports (3p)
Client activity management (3p)
User management (2p)
Sales workflow (3p)
Process sample: planning the releases
Now together with the customer, we make the first plan, dividing the work in two iterations:
Iteration #1: 10 p Client management (3p)
Product management (3p)
Sales leads management (4p)
Iteration #2: 11p
Sales reports (3p)
Client activity management (3p)
User management (2p)
Sales workflow (3p)
After we have a plan to deliver the 21 points features in 2 months, we start working, by starting on the first iteration, at the end of which we deliver features 1,2 and 3.
Process sample: delivering and customer wants more We now show the customer the first 3 features implemented, but he suddenly realizes that he needs more, then what was planned for the release. We start by adding what he wants to the list of features, which now becomes, after each of the new features are being estimated.
Client management (3p)
Product management (3p)
Sales leads management (4p)
Sales reports (3p)
Client activity management (3p)
User management (2p)
Sales workflow (3p)
Activity calendar (3p)
Forecast reports (3p)
Document templates and document merging (3p)
Process sample: changing/adapting the plan We cannot deliver all in the 2 months term, but we make a delivery after the two months and we plan another delivery after that will include other features that will make the system more compete. The new plan looks like:
Release #1: 2 months
Iteration #1: 10p
Client management (3p)
Product management (3p)
Sales leads management (4p)
Iteration #2: 11p Sales reports (3p)
Client activity management (3p)
User management (2p)
Forecast reports (3p)
Release #2 not defined fully yet
Iteration #3: 9p Sales workflow (3p)
Activity calendar (3p)
Document templates and document merging (3p)
Process sample: new requirements/new plan
Release #1: 2 months
Iteration #1: 10 pClient management (3p)
Product management (3p)
Sales leads management (4p)
Iteration #2: 11p
Sales reports (3p)
Client activity management (3p)
User management (2p)
Forecast reports (3p)
Release #2
Iteration #3 – 9p
Sales workflow (3p)
Activity calendar (3p)
Document templates and document merging (3p)
Iteration #4 – 10p
Contact communication management (3p)
Microsoft outlook integration (2p)
Sales processes (5p)
Iterations: benefits-
increase focus and the need to organize inside the team by give a near-term deadline Mark Twain: “Nothing focuses the mind like a noose”
-
good instrument for planning, tracking progressIf the product is presented each time, it is easy to see where the project is
-
minimize risks Agile thinking minimizes risks because it focuses on the most important and valuable features for the customer, and develops them first
-good instrument for managing changes in software At the end of an iteration, direction can be changed, and plans adapted to the new needs.
-good instrument to build trust By showing the customer the software after each iteration, he can see progress
Iterations: benefits (2) -allow learning and adapting
Because the customer sees the results after an iteration, he can better express his needs, and he better understands what’s possible and what’s cost effective
-are a good instrument for development At the end of an iteration, a set of features must be shown as working. This transfers the focus of the developers, from developing a system horizontally, layer by layer, from data access, to business and presentation layers, assembling the whole system at the end. Instead the focus is on delivering working features, developing them vertically on all layers.
-build confidence and motivate in the team One very important aspect in development, especially in the early stages of a project is an early victory. By delivering the first iteration, the team starts to see something positive happening and starts to build confidence that it will win. With each new iteration a new battle is won, getting the team closer and closer to winning the war.
-bring honesty Since iterations are short the customer sees the product developed quickly, delays are surfaced very early, not allowing them to grow into serious problems.
-good instrument to increase quality At the end of each iteration, a potentially shippable product must be shown to the customer. This focuses the team on keeping the quality high, never letting bugs and quality problems perpetuate.
Bad quality increasing costs dramatically (debugging time)
What is quality? In order to understand what quality is we must divide it into
external quality of a system and
internal quality, where external quality means what the customer thinks of the system, and internal quality is when the program is easy to change, extend and to maintain
External quality – whether the customer is happy by what he sees and feels
Problem: Poor external quality makes the customer send back the project for rework, and rework kills profits very fast.
Testing a system only at the end is not going to make the project deliverable faster, but in most cases it only shows it down. This does not mean that untested system should be delivered, but that testing should be started in min 1 of a project (acceptance tests, TDD, manual testing as the tools)
Solution: frequent feedback from the customer.
Tools:
Iterations and product presentation meetings. When each iteration is finished, the product’s planned features are demo-ed to the customer
Acceptance tests gathered from the customer, at the beginning of the iteration, to confirm at the end that what was asked for was implemented
Internal quality Internal quality – whether the project can be easily changed, maintained and extended.
Problem: “Nothing kills speed more effectively than poor internal quality” Martin Fowler - Planning Extreme Programming
Solution: fast feedback from the code
Tool: TDD – Test Driven Development – by writing all code test first, you end up with all the production code backed up by a series of regression tests. When you want to change something by running the regression suite of automated suite of tests, you can find out very fast whether you’ve broken something that was already implemented. This is the feedback from the code itself
Test Driven Development
TDD explained:
1. Write a test (specification for what the code must do – TDD design method)
2. Make it fail
3. Write the code to make it work
4. Refactor (improve the code)
5. Go to step 1
Benefits of TDD: -
fast feedback from code as the project increases, people can move ahead faster – projects cost less. When a system grows, the biggest problem is whether when someone fixes a bug,
-
debugging takes less, reducing costs. With TDD the number of bugs decreases, and also when bugs are fixed, they can be fixed faster (by making sure new ones are not introduced)
-
tests as documentation of what the code actually does
TDD vs. code and fix “To obtain good code, writing tests and code is faster then code alone” – Ron Jeffries, 2006
We tend to think adding automated tests the development time increases. Test+code time> code time. 1h+4h>4h
This thinking presumes that the code done in the 4 hours of development is bug free. That is bug free and will stay like that even if the system around it changes, gets bigger etc. Usually is not so 1h+4h>4h+x?
Sample
1 programmer paid 10£/week, needs to implement 1 feature estimated to 10 days
TDD: tests (15-25%) 2.5+10=12.5 days 25£
Code and fix: 10+5 debugging time =15 30£
Writing tests firsts focuses development, so many unneeded code is avoided so the additional 15-25% actually doesn’t exist
Not enough time, projects late - actually too much to do
Cause: In many cases, the problem with not enough time, is actually that one person has too many things to do in a limited amount of time.
Solution: eliminate waste and cutting overhead
By eliminating non crucial work, work that does not add immediate value to the customer, the people involved in a project will have more time, they will be able to be creative, focus on quality and deliver products at the customer on time.
What is waste in software development?
Taiichi Ohno’s (the father of Toyota Production System) said that anything that does not add value to a product, as perceived by the customer, is waste. Agile methodologies have emerged as a response to the chaos resulting from inappropriately used resources which waste time and energy.
Waste activities (from Lean Software Development-Mary, Tom Poppendieck)
partially done work
extra processes
extra features
switching tasks among workers (requiring additional learning curves)
waiting
motion and defects
Management activities
Not using the most productive tools
Waste activities (from Lean Software Development-Mary, Tom Poppendieck)
Partially done work Code, documents, activities that get done partially and are not carried out until their end, only waste important resources without adding any value for the client
Extra processes
“Do you ever ask, Is all that paperwork really necessary? Paperwork consumes resources. Paperwork slows down response time. Paperwork hides quality problems. Paperwork gets lost. Paperwork degrades and becomes obsolete. Paperwork that no one cares to read adds no value.
Many software development processes require paperwork for customer sign-off, or to provide traceability, or to get approval for a change. Does your customer really find this makes the product more valuable to them? Just because paperwork is a required deliverable does not mean that it adds value. If you must produce paperwork that adds little customer value, there are three rules to remember: Keep it short. Keep it high level. Do it off line. “ – Lean Software Development
Waste activities (from Lean Software Development-Mary, Tom Poppendieck)
Extra features 66% of the features of a system are never or rarely used. Many customers spend fortunes on features never used. This is the most efficient method to cut costs.
Switching tasks
A developer moved from one project to another needs time to adjust to the new project: the learning curve. In many cases the times are either bigger then it takes t actually fix the bug or do the new feature, and in most cases because of lack of knowledge on the project he breaks something existing. When moved back to the project he will need time again to readjust to the system he was working on. This is the biggest problem we are facing.The fastest way to complete two projects that use the same resources is to do them one at a time. – Lean Software Development
Waiting
Using a traditional sequential development process, means that teams wait on each other. The delays are propagated and amplified though the whole project. Working as much as possible in parallel, is much more efficient. Sequential development pairs very well with switching tasks amplifying the problems.
Value stream mapping chart (wait time vs work time)
Value stream maps often show that non-development activities are the biggest bottlenecks in a software development value stream.
In 1970 Winston Royce (inventor of the waterfall model)"[While] many additional development steps are required, none contribute as directly to the final product as analysis and coding, and all drive up the development costs."
Communication problems
Three categories:
-customer representatives
-management
-developers
Problems: Information too late, travelling too much
Too less or too much information (quantity vs. quality)
The specification document needs to much time to be built, and is over-complete in most cases (if the doc is big, the customer will read it later, adding to the amount of time unused)
It is hard to change and track changes in it
It is hard to actually see if the customer will accept it or not
Solution: replace documents with prioritized lists, details with acceptance tests
Send the list of items faster to the developers, and let them ask for more details – pull systems working in parallel
Reflective Improvement
CRUCIAL: Team looks back every iteration, and improves their process
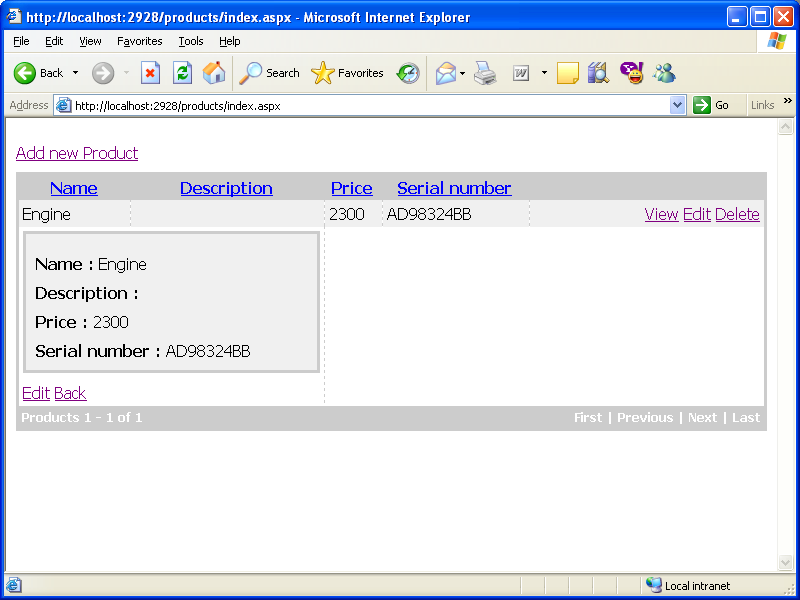
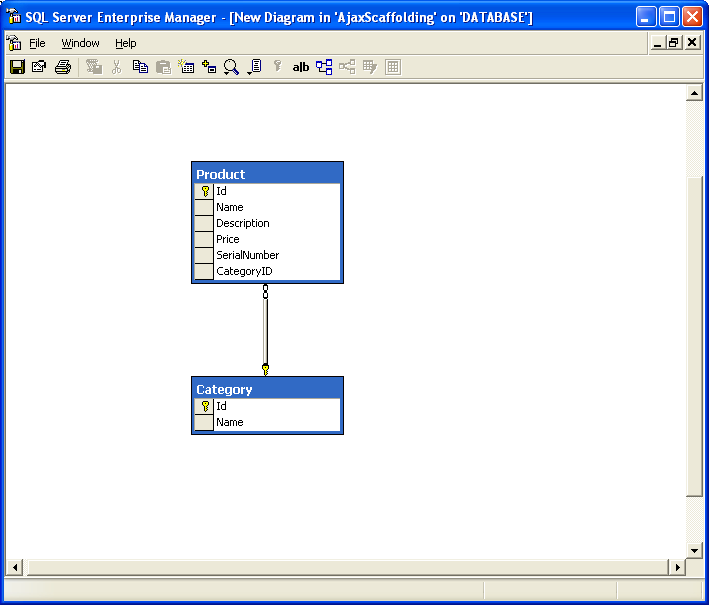
 then we add:
then we add:
 now viewing in place:
now viewing in place:

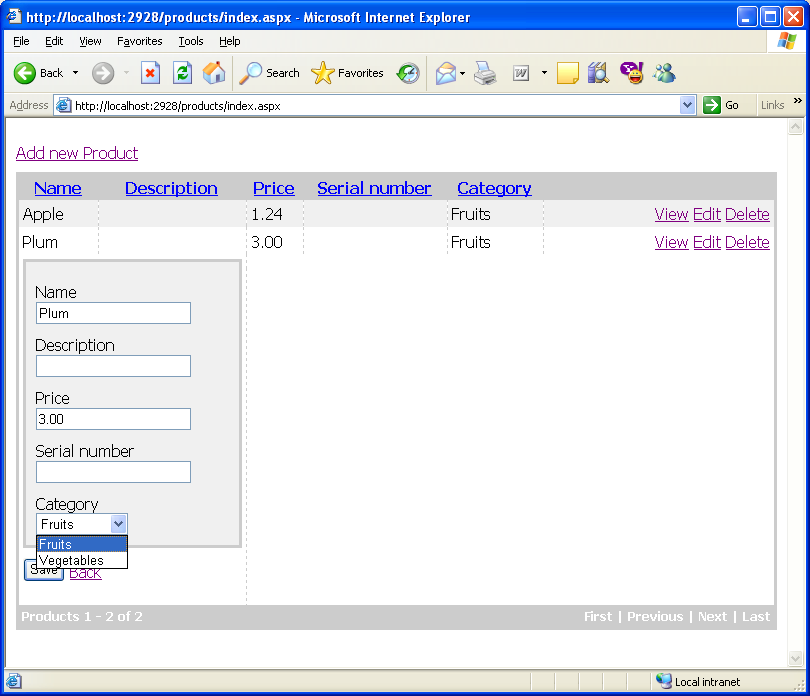
 and
and