2.1 Introduction
What is a methodology?
A methodology for software is a set of related rules, principles and practices that, once put in practice, can help deliver valuable software, to the client on time, over and over again.
Your methodology is everything you do regularly to get your software out. It includes who you hire, what you hire them for, how they work together, what they produce and how they share.
[Cockburn, 2004]
Characteristics of an agile methodology
Agile methodologies are characterized by close collaboration with the customer, and by delivering working, tested within fixed time intervals, called iterations, which usually lasts from one to four weeks. These practices help ensure that the software is developed according to the customer wishes, projects staying on track, and can also react well to changing requirements and priorities.
Working software is shown to the customer at the end of each iteration which provides a tangible mean to track project progress rather than with charts and reports. Written documentation is kept to a minimum, in favor of real-time, face to face verbal communication and close collaboration both within the team and with the customer. This close communication and frequent feedback loop with the client enables a continuous learning process in which the customer understands and participates in software development and the developers are kept close to the business domain of the customer.
2.2 Agile manifesto and principles
Throughout the 90’s several new “light weight” software methodologies emerged in reaction to the problems with the heavy methodologies used throughout the industry.
In 2001, Jim Highsmith and Robert C. Martin, organized a meeting of 17 people, many of them being founders of these “new” methodologies to discuss the similarities and differences of their methodologies, and establish a set of principles that were common to all. Thus the “agile” movement was born with the establishing of a manifesto and a set of 12 common practices that expressed the essence of what agile development is.
The agile manifesto
1. Individuals and interactions over processes and tools
The heavy, high ceremony processes with lots of process and documentation overhead, were found to produce less valuable software for the customers, than self organized teams of open minded individuals, who were interacting and focusing more on delivering software rather then strictly following the process.
2. Working software over comprehensive documentation
In many cases, vast amount of documentation was produced for different purposes, from gathering requirements, to tracking and showing progress to the client or to document what had been done, with people focusing on getting the right documents rather than the right software, for the customer, on time. They discovered that there is no better way to show progress, then showing the customer the software, because working, tested software does not leave room for misinterpretations.
Documentation can be helpful, but it is very important to do just enough of it for the needed purpose, staying focused on delivering software, instead of focusing on making the best documentation possible.
3. Customer collaboration over contract negotiation
In many cases, because of the virtual nature of software, clients cannot express their requirements very well at first, but they tend to become good at it as they see the software being built. This continuous learning of both the customer, about software, and for the developers about the customer’s business was proved to be a very good way to build software. By having everything negotiated and signed off from the beginning, the software’s purpose, from the client point of view, could be misunderstood. Collaborating directly with the client is usually a guarantee that the software that he needs is developed and that it is shaped as close to what he wants as possible.
4. Responding to change over following a plan
Plans are used to calm us down, to give us a direction to follow and as we go to let us know where we are by comparing the reality with the plan. But we need to be able to readapt the plan fast if the direction of the software being built has changed. Following a rigid plan, loses its calming purpose for both developers and customer, when it no longer reflects reality.
The principles
The principles of the agile manifesto are the ones that explain better, the practical side of agile manifesto. They show which principles are followed in all agile methodologies. They represent a more pragmatic approach to what must be done to become agile.
1. Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.
2. Welcome changing requirements, even late in development. Agile processes harness change for the customer's competitive advantage.
3. Deliver working software frequently, from a couple of weeks to a couple of months, with a preference to the shorter timescale.
4. Business people and developers must work together daily throughout the project.
5. Build projects around motivated individuals. Give them the environment and support they need, and trust them to get the job done.
6. The most efficient and effective method of conveying information to and within a development team is face-to-face conversation.
7. Working software is the primary measure of progress.
8. Agile processes promote sustainable development. The sponsors, developers, and users should be able to maintain a constant pace indefinitely.
9. Continuous attention to technical excellence and good design enhances agility.
10. Simplicity--the art of maximizing the amount of work not done--is essential.
11. The best architectures, requirements, and designs emerge from self-organizing teams.
12. At regular intervals, the team reflects on how to become more effective, then tunes and adjusts its behavior accordingly.
The agile alliance
The agile alliance defines itself as:
“a non-profit organization that supports individuals and organizations who use agile approaches to develop software. Driven by the simple priorities articulated in the agile manifesto, agile development approaches deliver value to organizations and end users faster and with higher quality”.
2.3 Agile methodologies, practices, properties and tools
There are, as Martin Fowler said, more “flavors” of agile methodologies.
- SCRUM
-XP - Extreme Programming
-Crystal Family
-Lean Software Development
-Adaptive Software Development
-AMDD - Agile Modeling Driven Development
-FDD – Feature Driven Development
-DSDM
All agile methodologies are based on a set of rules, values, principles and practices specific to each of them, or that have been influenced or evolved with practices from other agile methodologies. Each methodology has a set of “must do” and a set of “could try” practices and tools, thus showing what the core of the methodology is and how it could be customized and adapted.
Most of the authors invite practitioners to use practices from the other methodologies, when it comes to an area that is not specifically covered by the methodology they propose, or where they leave much flexibility.
SCRUM and XP dominate the market at the time, being the best known and the most used, but it is important to have an overview of the entire range of agile methodologies. Mixing practices from more agile methodologies can better adapt to one’s needs thus making his process more customized and more efficient.
2.4 XP
Extreme programming is probably the most known (and controversial) agile methodology, being defined by Kent Beck, in 1999 in “Extreme Programming Explained: Embrace Change, First Edition”, after being shaped along Ron Jeffries, Ward Cunningham, Martin Fowler or Robert C. Martin throughout the late 90’s, especially in a famous Chrysler project called C3, where the basis of it had been put into practice.
Extreme programming is based on a set of values, principles and practices, that are recommended to be followed, covering all aspects from communication, to organization, quality control and coding. It is the methodology that puts the highest accent on testing, and especially automated testing from all software disciplines known.
Values, Variables, Principles and Practices
XP has 5 values, on which it is based: communication, simplicity, feedback, courage and respect.
The most important practices of XP are:
- small releases
- the planning game
- refactoring
- test driven development
- pair programming
- sustainable peace
- team code ownership
- coding standard
- simple design
- metaphor
- continuous integration
- on-site customer
The key principles, on which XP is based, are: rapid feedback, assume simplicity, incremental change, embrace change and quality work
How do people work in XP?
In XP, projects are developed by collocated teams, usually with 4-10 developers, delivering the work to the client or onto the market, every 2 to 4 months, calling these timed units, releases. These releases are also divided in a set of iterations, each lasting from one to 4 weeks (most common are 2 and 3 week iterations) and at the end of which, a part of the entire product, is delivered. The end result of such an iteration should be a high quality piece of software, that could be potentially deployed into a production environment.
In XP, the client has to be collocated with the team, to be able to answer questions and “steer” the direction of the project all the time. The client is called “the customer” and the technique described above, is called “on site customer”. As a consequence of this collocation, feedback is very fast, so the project doesn’t derail, and the need for written functional specifications is less obvious. The unit for gathering requirements from the client that is also later used in planning is the user story and it usually represents a valuable feature for the client. It is not written in very much detail and most times it is very brief, acting more like a reminder for the customers and programmers to talk about it and be able to estimate and implement it.
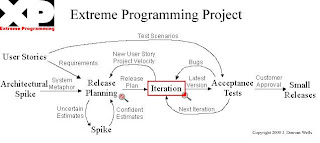
In XP software is developed in cycles; every few months a release is being planned then built trough several succeeding iterations, then the product developed so far deployed to the customer finalizing one cycle and starting another if necessary. At the beginning, the project is planned for the next release (2-4 months in advance). The user stories are written with the customer, and then these user stories are estimated by the programmers, providing the client the “cost” for each of these pieces of functionality. Based on these costs the customer can then give the priorities, putting the most important one to be developed first, so the most valuable features for the client are being developed and delivered the fastest. The user stories in the plan, after being estimated and prioritized are now divided between the iterations in the planned release.
At the beginning of each iteration or release, the customer can change the plan and readapt it to his needs, re-prioritizing the list of user stories, being able to change the direction, by bringing forward user stories from other iterations, adding new ones or dropping some of them, then the programmers re-estimate the work, redefine the plan.
Going deeper into detail for user stories is done trough verbal communication between programmers and the customer. Programmers estimate the user stories by dividing them into programming tasks. The customer writes acceptance tests or customer tests as they are called in XP that will demonstrate by passing that what was requested was really implemented. Many times these acceptance tests become automated tests.
Once the iteration has been planned, the programmers divide the user stories or tasks among them and then write the code in pairs or two people (pair-programming) writing automated tests for anything that could possibly break, integrating the pieces of code that each pair delivers and building the system and running the suite of tests automatically as often as possible. The code is written after a coding standard document, and the pairs of programmers are changed often so that each programmer can work on more parts of the system and pairing with more colleagues throughout the project, thus knowing better what is happening in it.
In XP, each programmer can change every piece of code, if he needs to, as there is no individual code ownership, but all the developers own all the code, this technique is called collective ownership.
The architecture or design of the code is not built up front like in traditional software engineering models, although risks are being evaluated (especially by building prototypes called spikes, but not necessarily at the beginning) but is actually emerging from the code, as this code is continually refactored to be the simplest possible (one of XP values is simplicity) and using the YAGNI (You Ain’t Gonna Need It) technique, focusing on what the code needs to deliver now rather then what could be needed in the future. When the changes will be needed, the code will be refactored to accommodate them, as refactoring is easy because of the extensive automated test suites that can instantly say if a change has broken some existing functionality and secondly because rotating the programmers in the pairs facilitates better knowledge of the whole system for all the programmers.
A special case is when a customer wants software and has a deadline for it which cannot be negotiated, but the amount of features he wants clearly need more time, than the specified deadline. In such a scenario, the customer and the developers sit together and first get the list of user stories the customer wants and then the developers estimate the cost of each. The customer is then asked to choose from that list enough user stories to fill the time until the first deadline. The rest of the user stories will be developed in another release after the first release has been delivered. This special case exposes very well the practice called negotiating scope.
XP (and other practices) strongly believes in sustainable peace, where projects are developed at a sustainable and constant rhythm of work, doing as much as possible in 40 hour weeks, without lows and highs in the number of hours needed throughout the development of the project, and this can be achieved applying the practices described above.
2.5 SCRUM
SCRUM is an iterative and incremental methodology that was developed starting from project management problems, by three people: Ken Schwaber, Jeff Sutherland and Mike Beedle, since 1993, and it has been proven as a great way to produce successful software continuously with small and large projects on a wide range of companies.
SCRUM is based on 5 values: commitment, focus, openness, respect and courage.
How does a SCRUM team work?
SCRUM teams and key roles
A SCRUM team is usually of four to seven developers. All these developers work together, being self organized without any intervention from upper management on individual responsibilities (who does what, who designs, who tests), all these activities are decided and performed inside the team. The developers have no fancy job names like architect, tester, programmer, etc.
A SCRUM master, is the equivalent of a project manager in traditional software development processes, but the way he does his job is very different. He is more a leader than a manager, letting the team self organize and having the primary goal in removing whatever obstacles the team would have when trying to deliver valuable software to the client. The SCRUM master serves the team, rather than imposing directions to it.
In SCRUM, the role of the client or the customer is called, the product owner. He is working with the team in defining and refining requirements, which are kept in a product backlog, each feature or item in there being called backlog item. His job is to produce the backlog items and to prioritize them, so that the highest value can be delivered by the team first.
Planning sprints
The product backlog is the master list of all functionality desired in the product.
[Mike Cohn, 2004]
A project starts in SCRUM with gathering all the important features that the product owner thinks will be needed in the product and all of them are put in the product backlog. Unlike traditional requirements gathering techniques, it is not important to get all the features into the product backlog at the beginning because the product backlog can be added to, updated and priorities changed in the future as the product owner starts to see the product learning more about the software product while the developers are also learning more about the business. This allows the customer to drive the product according to the real needs he has at a certain time. It is important however to get as many features in the backlog at first, enough for the product owner to be able to prioritize the work and for the developers to develop in the first monthly iteration called sprint.
Projects are developed in SCRUM, using one month iterations called sprints. At the end of each sprint a potentially shippable product is delivered and presented to the product owner. Then another sprint is planned, built and delivered in the next 30 days and so on until the project is finished.
Each sprint starts with a sprint planning meeting where all the parties involved (the program owner, developers and SCRUM master) participate, but other interested parties like management or customer representatives can also be present. A meeting like this usually lasts up to an entire day, and is divided into two parts.
Part one of the planning meeting is when the product owner describes the most valuable items from the remaining features in the product backlog. This is done so that the features are described in more detail, so that later they can be estimated easier by the development team. When the team has something to clear up, this is done trough questions and direct conversations with the product owner. Not all remaining features are important to be described here by the customer, but enough from the product backlog, that can possibly fit in this sprint, choosing the most valuable first. The remaining items will be discussed in the future sprint planning meetings.
Trough this activity, the team and the product owner define where they want to get to when this sprint will be finished. Mike Cohn refers to this as defining the sprint goal. This is the expected and will be compared at the end of the iteration with the actual.
Part two of the sprint planning meeting is done to let the team see how much from the product backlog can they built in this sprint. For this the team discusses what they heard separately, seeing how much effort each item will need and seeing how many items fit into this sprint. Since the product backlog is sorted, by the product owner, descending on the basis of priority, the team can draw a line under the last item that can be included in the sprint. All these items will now be moved to the sprint backlog, in order to be built having the product owner approve the list. In some cases this list can be negotiated as some of the items might be more costly (in time) than others and based on this the product owner can reprioritize what needs to be done.
After the product backlog items are added to the sprint backlog, this list is sealed. Only in exceptional cases can it be modified, or items added to it, but this only with the explicit accept from the team.
The sprint backlog is different from the product backlog as in the sprint backlog, after the items have been moved from the product backlog, the sprint backlog items can be divided into programming tasks that are also items. The product backlog needs to be understood by the customer, but the sprint backlog can and should include tasks that can be understood only by the programmers and that help organize their work better.
Daily SCRUM meetings
At the beginning of each day, the team gets together for 15-30 minutes, to discuss the status of the project. This meeting goal cannot be derailed in any way, and is usually held with everyone standing in a circle, with each team member being asked the following questions by the SCRUM master:
- What did you do yesterday?
- What will you do until the tomorrow daily SCRUM?
- What prevents you from doing your work?
The daily meeting’s main purpose is for all to know where the project stands and for each to commit to something in front of the others, not the SCRUM master. The SCRUM master needs to do whatever possible to eliminate the obstacles raised by the answers to the 3rd question.
The daily meetings can be attended by other stake holders such as managers, even CEO to see progress; however they are not allowed to speak, just to hear. This is also known as the “pigs and chicken” technique, with the team being the pigs and the management being the chickens, being inspired from a short very relevant story:
A pig and a chicken discussed the name of their new restaurant. The chicken suggested Ham n' Eggs. "No thanks," said the pig, "I'd be committed, but you'd only be involved!"
[Larman, 2005]
Developing
SCRUM does not impose strict engineering practices like XP does, but it emphasizes the need for quality work, automated tests and daily builds of the system. Many teams do use TDD, Continuous Integration, even user stories and other practices from XP with great success, having a mixture of agile methodologies, as these agile methodologies have evolved together, XP planning game being influenced by SCRUM, and developing very successful projects that way.
Product presentation meeting or sprint review meeting
When a sprint has been finished (at the end of the 30 days) a sprint review meeting is held to compare the expected with the actual built, together with the entire team, the SCRUM master, the product owner being present and other stake holders. The meeting is very informal and PowerPoint slides and presentations are strictly being prohibited, the focus being on showing progress, by showing the software, going trough all newly developed backlog items from this sprint. After all, what better way to show progress than the product itself?
An emphasis is also put on getting feedback after seeing the product demo. Craig Larman says:
Feedback and brainstorming on future directions is encouraged, but no commitments are made during the meeting. Later at the next Sprint Planning meeting, stakeholders and the team make commitments
[Larman, 2005]
Doing it all over again
After the sprint has been finished and the actual result presented to the product owner and the other interested parties, it is time to take things from the beginning with the next sprint starting with the sprint planning meeting. This is done over and over again until the customer considers that the product is finished.
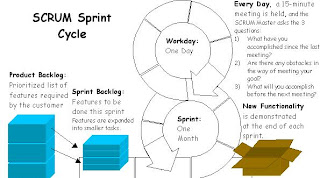
Scaling SCRUM
Usually a SCRUM team consists of four to seven team members. This does raise the question of how does SCRUM work when more then 7 developers are needed. The answer is in having more SCRUM teams, with daily meetings also being held across teams, each team sending a representative to these meetings.
Projects with several hundred developers have been developed using SCRUM, from small projects to large multi country teams with 330 to 600 developers involved, as the IDX project [Larman, 2005], [Cohn, 2004].
SCRUM is a project management method that exceeds the borders of software development being used in other domains as well. It is a “simple process for managing complex projects” in general, very well suited for software.
2.6 Crystal Clear
Introduction
Since 1990, methodology anthropologist Alistair Cockburn has studied all over the world how successful teams of developers build and deliver software, over and over again, and listed his findings in a methodology family called Crystal, which is composed of more methodologies, divided by the size of the team and also by the importance of the project, varying from the lightest: Crystal Clear to heavier methodologies, that get darker colors, such as yellow, Orange, Red etc, having the author believe that heavier processes are needed for larger projects, starting from the concept that one methodology cannot cover all aspects of software development.
What is Crystal Clear?
CC aims to be a simple and tolerant set of rules that puts the project on the safety zone. It is, if you will, the least methodology that could possibly work, because it shows much tolerance (Cockburn, 2005)
How do Crystal Clear teams work?
Properties, Tools and Practices
CC is based on a set of seven properties, which deeply influence development: frequent delivery, reflective improvement and close communication, personal safety, focus, early access to expert users and technical environment with automated tests, configuration management and frequent integration, but only the first 3 are a must.
Following CC the developers are organized in teams consisting of 2-8 members, with at least one level 3 developer, usually sitting in the same room, facing each other in order to facilitate verbal communication as much as possible. They sit side by side and collaborate often, this technique being called side-by-side programming. This is very similar with XP’s pair programming but differs from it as each team member has his own computer and can develop alone, or with the colleague on the right or on the left.
The development is divided into periods lasting from 1-4 months called deliveries, at the end of which the software will be deployed to the end users. Between these deliveries, at regular intervals, called iterations, the customer representatives are shown the working product and the feedback from them is gathered.
Requirements are obtained from the customer as “light” use cases and are obtained and prioritized together, with the customer and then a delivery plan is built for the next delivery.
CC teams constantly look back and improve the way they are working, both at the end of the iteration but also in the middle of it. This technique is put in practice by dividing actions done in 3 lists: things that worked and should be kept, things that didn’t work and should be dropped and things that could be tried next.
The design activity, which is continuous throughout the project, is done on a whiteboard, and if there’s need to keep a record of it, it is photographed and included into a document straight from the whiteboard.
The code being written is deliberately architected so that it can support a fully regression automated testing suite. These regression tests give them the possibility to do lots of changes and to adapt easily to shifts in direction of the product being developed, but the coding style is in the hand of the developers, they being the one that decide what best suites them. There are also as many integrations as possible putting together all the parts of the system and running the whole regression suite of tests.
Any team member can feel safe always telling what he thinks, like telling a manager that a schedule is unrealistic or a colleague that his design needs rework. Alistair Cockburn calls this the first step toward trust.
CC teams always focus on what’s the most important thing that needs to be taken care of now, and always have easy access to expert users or the client, that can always be asked to clear misunderstandings, to plan the next deliverable product or to receive feedback from them.
Besides the 7 properties of CC, it also comes with a series of recommended strategies and techniques, to be able to deliver value to the client fast. Some of them are very similar, inspired from or have evolved with practices from other agile methodologies.
There are 4 strategies: exploratory 360, walking skeleton, incremental rearchitecture and information radiators and 9 techniques: methodology shaping, reflection workshop, blitz planning, Delphi estimation using expertise rankings, daily stand up meetings, essential interaction design, process miniature, side by side programming and burn charts.
2.7 Lean Software Development
Lean software development is not a day to day strict practice methodology, but rather a set of 7 principles and 22 tools that can be used to successfully manage a project. Lean software development comes to complete the practices from other agile methodologies, with lessons learned in other industries, that are more advanced and mature that the software development branch. Jim Highsmith, said about lean software development that it presents a toolkit for project managers, team leaders, and technology managers who want to add value rather then become roadblocks to their project teams.
Origins
Much before the software industry, the auto industry had given up the waterfall model, in favor of a more lightweight but efficient model, that can produce results faster and in a concurrent manner. Mary and Tom Poppendieck published “Lean Software Development: An Agile Toolkit” in 2003,doing a wonderful job in adapting the lean principles, used in manufacturing, to software development. They have proved these practices, developing and managing software projects, demonstrating that not the inspiration from another industry was bad (some advocates of the agile methodologies have claimed that the inspiration in the 60-70’s from mechanical and construction engineering caused many problems in software), but that the mistake was not evolving with manufacturing and other industries when they dropped the waterfall model.
Mary and Tom also showed that some of the previous attempts to adapt lean principles to software failed because they were started wrong, without realizing the difference between development and product manufacturing.
The 7 principles
Eliminate waste – Taiichi Ohno’s (the father of Toyota Production System) said that anything that does not add value to a product, as perceived by the customer is waste. All agile methodologies have emerged as a response to chaos where the amount of wrongly used resources generates lots of overhead and waste , thus having a method to identify and cut unproductive activities, is considered, for software development as well, a very important tool.
In software development, the following are considered waste: partially done work, extra processes, extra features (never needed or used), task switching (people learning one system, then moving to another where another learning curve is needed), waiting, motion and defects.
Value stream mapping is the chart that enables you to simply see the periods that add value and the periods where time is wasted. Put in practice, this is a tremendous tool, showing huge gaps between value and waste.
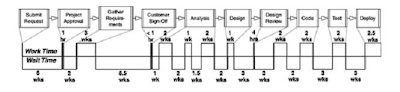
[Value stream mapping in traditional processes, from “Lean Software Development: An Agile Toolkit”]
Amplify learning
Software development is a continuous learning and adapting activity between the customer and the developers, which learn from each other, communicate better and thus build better and more useful software. Feedback (tool 3) amplifies the learning process and because it is based
Synchronization (tool 5) allows concurrent development. Good synchronization is achieved with the customer through iterations (tool 4) and with the colleagues mostly with frequent code integration and reverse testing sessions. Synchronization is achieved better if we start from the interaction point first, from the interfaces of the different components.
Set based development (tool 6) is one of the greatest lessons we can learn about communication. Saying what the constrains of a system that needs to be built are allows the developer of the system to come up with more choices, with a set of solutions. Combined with further requirements, from that set of solutions the one that passes all constrains will emerge. If we ask specifically for a choice we might miss several alternatives and find ourselves stuck.
Decide as late as possible
Deciding for the future has been proved wrong as it can never predict changes and makes the cost of change enormous. Deciding later based on more information and keeping your options open (Options thinking – tool 7) is a better option. The last responsible moment (tool 8) enables you to take responsible decisions (making decisions – tool 9) late but not too late.
Deliver as fast as possible
Until recently rapid software development has not been valued; taking a careful, don’t make any mistakes approach has seemed to be more important
[Poppendieck and Poppendieck, 2003]
Lean product manufacturing and agile software development have proved that fast delivery is possible and leads to more satisfactory results for the customer. Recommended tools inspired from lean manufacturing are: Pull systems (tool 10), queuing theory (tool 11) and cost of change (tool 12)
Empower the team
Highly motivated, self organized teams, that have power to take decisions and put their ideas into practice, being lead by people with expertise, have always been a recipe for success (Self determination (tool 13), Motivation (tool 14), Leadership (tool 15), Expertise (tool 16))
Build integrity in
Perceived and conceptual integrity is what we understand by external and internal quality of a software product. If the integrity (tool 17) perceived by the customer is good, then the software that was asked for was built and is of high quality, and if the conceptual quality (tool 18) is goof, then the product’s internal quality is good, meaning that it can be extended, maintained and kept longer in use. The two fundamental practices at the base of integrity are testing (tool 20) and refactoring (tool 19).
See the whole
Making parts of a whole, at the highest quality does not necessary mean that when they are assembled together, the resulting system is at the highest quality and as required. Focusing on the whole system, helps making the parts better suited to work with each other and to compose a better system. The tools mentioned in achieving these are: Measurements (tool 21) and Contracts (tool 22)
Lean software development principles and tools should be in every agilist’s pocket no matter what methodology they follow, as they represent invaluable advice and proven practices to enhance efficiency.
2.8 AMDD – Agile Model Driven Development
AMDD is a light-weight approach for enhancing modeling and documentation efforts for other agile software processes such as XP and RUP [Ambler 2005], being extremely valuable in situations where written documentation and modeling are required. It is based on a set of principles, values and practices, which explain and enhance the role of modeling and documentation, in agile methodologies, based on the sufficiency principle, leaving unnecessary detail out.

Its author, Scott Ambler, a very active member of the agile community with great contributions especially on agile modeling, agile databases and database refactoring techniques, emphasizes in AMDD, that all agile methodologies include modeling, from the simple user stories and CRC cards to the automated tests as primary artifacts: acceptance tests as primary artifacts for requirements and unit tests as detailed design artifacts.
2.9 DSDM – Dynamic Systems Development Method
DSDM is an agile methodology, developed since 1994, and continuously improved by a non profit organization, called the DSDM consortium.
DSDM, breaks from traditional software methodologies, looking the work, from an entire different perspective:
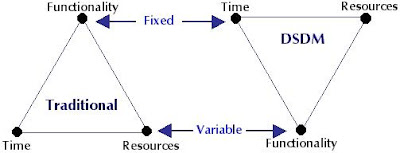
DSDM is based on the following as core concepts: active user involvement, team empowered to make decisions, frequent releases, iterative development that are user feedback driven, reversible changes, requirements defined early at a high level, integrated testing, essential communication and collaboration, 20%/80% rule and having the goal to fit the business purpose.
2.10 FDD – Feature Driven Development
FDD is an agile methodology, developed by Jeff DeLuca and Peter Code, since around 1997, that puts bigger emphasize on modeling and offers good predictability in projects with more stable requirements, consisting of two main stages: discovering the features to implement and implementing them one by one.
The first stage, discovering the features, is done with the customers on site and marks the features to be implementing using UML.
The second stage develops the features, in 1-3 week iterations, in which more features to be done, are packaged. At the end of each iteration, the software produced is considered shippable.
2.11 Adaptive Software Development
Jim Highsmith is one of the most respected book authors and lightweight methodology advocates, in the agile community. He wrote a series of books on agile software development and agile software management, defining the Adaptive methodology, where he promotes the need for the continuous evolution and adaptation of the process used. He states that software development should be developed incrementally and iterative, trough repetitive cycles that include 3 stages: speculate, collaborate and learn.
What is a methodology?
A methodology for software is a set of related rules, principles and practices that, once put in practice, can help deliver valuable software, to the client on time, over and over again.
Your methodology is everything you do regularly to get your software out. It includes who you hire, what you hire them for, how they work together, what they produce and how they share.
[Cockburn, 2004]
Characteristics of an agile methodology
Agile methodologies are characterized by close collaboration with the customer, and by delivering working, tested within fixed time intervals, called iterations, which usually lasts from one to four weeks. These practices help ensure that the software is developed according to the customer wishes, projects staying on track, and can also react well to changing requirements and priorities.
Working software is shown to the customer at the end of each iteration which provides a tangible mean to track project progress rather than with charts and reports. Written documentation is kept to a minimum, in favor of real-time, face to face verbal communication and close collaboration both within the team and with the customer. This close communication and frequent feedback loop with the client enables a continuous learning process in which the customer understands and participates in software development and the developers are kept close to the business domain of the customer.
2.2 Agile manifesto and principles
Throughout the 90’s several new “light weight” software methodologies emerged in reaction to the problems with the heavy methodologies used throughout the industry.
In 2001, Jim Highsmith and Robert C. Martin, organized a meeting of 17 people, many of them being founders of these “new” methodologies to discuss the similarities and differences of their methodologies, and establish a set of principles that were common to all. Thus the “agile” movement was born with the establishing of a manifesto and a set of 12 common practices that expressed the essence of what agile development is.
The agile manifesto
1. Individuals and interactions over processes and tools
The heavy, high ceremony processes with lots of process and documentation overhead, were found to produce less valuable software for the customers, than self organized teams of open minded individuals, who were interacting and focusing more on delivering software rather then strictly following the process.
2. Working software over comprehensive documentation
In many cases, vast amount of documentation was produced for different purposes, from gathering requirements, to tracking and showing progress to the client or to document what had been done, with people focusing on getting the right documents rather than the right software, for the customer, on time. They discovered that there is no better way to show progress, then showing the customer the software, because working, tested software does not leave room for misinterpretations.
Documentation can be helpful, but it is very important to do just enough of it for the needed purpose, staying focused on delivering software, instead of focusing on making the best documentation possible.
3. Customer collaboration over contract negotiation
In many cases, because of the virtual nature of software, clients cannot express their requirements very well at first, but they tend to become good at it as they see the software being built. This continuous learning of both the customer, about software, and for the developers about the customer’s business was proved to be a very good way to build software. By having everything negotiated and signed off from the beginning, the software’s purpose, from the client point of view, could be misunderstood. Collaborating directly with the client is usually a guarantee that the software that he needs is developed and that it is shaped as close to what he wants as possible.
4. Responding to change over following a plan
Plans are used to calm us down, to give us a direction to follow and as we go to let us know where we are by comparing the reality with the plan. But we need to be able to readapt the plan fast if the direction of the software being built has changed. Following a rigid plan, loses its calming purpose for both developers and customer, when it no longer reflects reality.
The principles
The principles of the agile manifesto are the ones that explain better, the practical side of agile manifesto. They show which principles are followed in all agile methodologies. They represent a more pragmatic approach to what must be done to become agile.
1. Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.
2. Welcome changing requirements, even late in development. Agile processes harness change for the customer's competitive advantage.
3. Deliver working software frequently, from a couple of weeks to a couple of months, with a preference to the shorter timescale.
4. Business people and developers must work together daily throughout the project.
5. Build projects around motivated individuals. Give them the environment and support they need, and trust them to get the job done.
6. The most efficient and effective method of conveying information to and within a development team is face-to-face conversation.
7. Working software is the primary measure of progress.
8. Agile processes promote sustainable development. The sponsors, developers, and users should be able to maintain a constant pace indefinitely.
9. Continuous attention to technical excellence and good design enhances agility.
10. Simplicity--the art of maximizing the amount of work not done--is essential.
11. The best architectures, requirements, and designs emerge from self-organizing teams.
12. At regular intervals, the team reflects on how to become more effective, then tunes and adjusts its behavior accordingly.
The agile alliance
The agile alliance defines itself as:
“a non-profit organization that supports individuals and organizations who use agile approaches to develop software. Driven by the simple priorities articulated in the agile manifesto, agile development approaches deliver value to organizations and end users faster and with higher quality”.
2.3 Agile methodologies, practices, properties and tools
There are, as Martin Fowler said, more “flavors” of agile methodologies.
- SCRUM
-XP - Extreme Programming
-Crystal Family
-Lean Software Development
-Adaptive Software Development
-AMDD - Agile Modeling Driven Development
-FDD – Feature Driven Development
-DSDM
All agile methodologies are based on a set of rules, values, principles and practices specific to each of them, or that have been influenced or evolved with practices from other agile methodologies. Each methodology has a set of “must do” and a set of “could try” practices and tools, thus showing what the core of the methodology is and how it could be customized and adapted.
Most of the authors invite practitioners to use practices from the other methodologies, when it comes to an area that is not specifically covered by the methodology they propose, or where they leave much flexibility.
SCRUM and XP dominate the market at the time, being the best known and the most used, but it is important to have an overview of the entire range of agile methodologies. Mixing practices from more agile methodologies can better adapt to one’s needs thus making his process more customized and more efficient.
2.4 XP
Extreme programming is probably the most known (and controversial) agile methodology, being defined by Kent Beck, in 1999 in “Extreme Programming Explained: Embrace Change, First Edition”, after being shaped along Ron Jeffries, Ward Cunningham, Martin Fowler or Robert C. Martin throughout the late 90’s, especially in a famous Chrysler project called C3, where the basis of it had been put into practice.
Extreme programming is based on a set of values, principles and practices, that are recommended to be followed, covering all aspects from communication, to organization, quality control and coding. It is the methodology that puts the highest accent on testing, and especially automated testing from all software disciplines known.
Values, Variables, Principles and Practices
XP has 5 values, on which it is based: communication, simplicity, feedback, courage and respect.
The most important practices of XP are:
- small releases
- the planning game
- refactoring
- test driven development
- pair programming
- sustainable peace
- team code ownership
- coding standard
- simple design
- metaphor
- continuous integration
- on-site customer
The key principles, on which XP is based, are: rapid feedback, assume simplicity, incremental change, embrace change and quality work
How do people work in XP?
In XP, projects are developed by collocated teams, usually with 4-10 developers, delivering the work to the client or onto the market, every 2 to 4 months, calling these timed units, releases. These releases are also divided in a set of iterations, each lasting from one to 4 weeks (most common are 2 and 3 week iterations) and at the end of which, a part of the entire product, is delivered. The end result of such an iteration should be a high quality piece of software, that could be potentially deployed into a production environment.
In XP, the client has to be collocated with the team, to be able to answer questions and “steer” the direction of the project all the time. The client is called “the customer” and the technique described above, is called “on site customer”. As a consequence of this collocation, feedback is very fast, so the project doesn’t derail, and the need for written functional specifications is less obvious. The unit for gathering requirements from the client that is also later used in planning is the user story and it usually represents a valuable feature for the client. It is not written in very much detail and most times it is very brief, acting more like a reminder for the customers and programmers to talk about it and be able to estimate and implement it.

In XP software is developed in cycles; every few months a release is being planned then built trough several succeeding iterations, then the product developed so far deployed to the customer finalizing one cycle and starting another if necessary. At the beginning, the project is planned for the next release (2-4 months in advance). The user stories are written with the customer, and then these user stories are estimated by the programmers, providing the client the “cost” for each of these pieces of functionality. Based on these costs the customer can then give the priorities, putting the most important one to be developed first, so the most valuable features for the client are being developed and delivered the fastest. The user stories in the plan, after being estimated and prioritized are now divided between the iterations in the planned release.
At the beginning of each iteration or release, the customer can change the plan and readapt it to his needs, re-prioritizing the list of user stories, being able to change the direction, by bringing forward user stories from other iterations, adding new ones or dropping some of them, then the programmers re-estimate the work, redefine the plan.
Going deeper into detail for user stories is done trough verbal communication between programmers and the customer. Programmers estimate the user stories by dividing them into programming tasks. The customer writes acceptance tests or customer tests as they are called in XP that will demonstrate by passing that what was requested was really implemented. Many times these acceptance tests become automated tests.
Once the iteration has been planned, the programmers divide the user stories or tasks among them and then write the code in pairs or two people (pair-programming) writing automated tests for anything that could possibly break, integrating the pieces of code that each pair delivers and building the system and running the suite of tests automatically as often as possible. The code is written after a coding standard document, and the pairs of programmers are changed often so that each programmer can work on more parts of the system and pairing with more colleagues throughout the project, thus knowing better what is happening in it.
In XP, each programmer can change every piece of code, if he needs to, as there is no individual code ownership, but all the developers own all the code, this technique is called collective ownership.
The architecture or design of the code is not built up front like in traditional software engineering models, although risks are being evaluated (especially by building prototypes called spikes, but not necessarily at the beginning) but is actually emerging from the code, as this code is continually refactored to be the simplest possible (one of XP values is simplicity) and using the YAGNI (You Ain’t Gonna Need It) technique, focusing on what the code needs to deliver now rather then what could be needed in the future. When the changes will be needed, the code will be refactored to accommodate them, as refactoring is easy because of the extensive automated test suites that can instantly say if a change has broken some existing functionality and secondly because rotating the programmers in the pairs facilitates better knowledge of the whole system for all the programmers.
A special case is when a customer wants software and has a deadline for it which cannot be negotiated, but the amount of features he wants clearly need more time, than the specified deadline. In such a scenario, the customer and the developers sit together and first get the list of user stories the customer wants and then the developers estimate the cost of each. The customer is then asked to choose from that list enough user stories to fill the time until the first deadline. The rest of the user stories will be developed in another release after the first release has been delivered. This special case exposes very well the practice called negotiating scope.
XP (and other practices) strongly believes in sustainable peace, where projects are developed at a sustainable and constant rhythm of work, doing as much as possible in 40 hour weeks, without lows and highs in the number of hours needed throughout the development of the project, and this can be achieved applying the practices described above.
2.5 SCRUM
SCRUM is an iterative and incremental methodology that was developed starting from project management problems, by three people: Ken Schwaber, Jeff Sutherland and Mike Beedle, since 1993, and it has been proven as a great way to produce successful software continuously with small and large projects on a wide range of companies.
SCRUM is based on 5 values: commitment, focus, openness, respect and courage.
How does a SCRUM team work?
SCRUM teams and key roles
A SCRUM team is usually of four to seven developers. All these developers work together, being self organized without any intervention from upper management on individual responsibilities (who does what, who designs, who tests), all these activities are decided and performed inside the team. The developers have no fancy job names like architect, tester, programmer, etc.
A SCRUM master, is the equivalent of a project manager in traditional software development processes, but the way he does his job is very different. He is more a leader than a manager, letting the team self organize and having the primary goal in removing whatever obstacles the team would have when trying to deliver valuable software to the client. The SCRUM master serves the team, rather than imposing directions to it.
In SCRUM, the role of the client or the customer is called, the product owner. He is working with the team in defining and refining requirements, which are kept in a product backlog, each feature or item in there being called backlog item. His job is to produce the backlog items and to prioritize them, so that the highest value can be delivered by the team first.
Planning sprints
The product backlog is the master list of all functionality desired in the product.
[Mike Cohn, 2004]
A project starts in SCRUM with gathering all the important features that the product owner thinks will be needed in the product and all of them are put in the product backlog. Unlike traditional requirements gathering techniques, it is not important to get all the features into the product backlog at the beginning because the product backlog can be added to, updated and priorities changed in the future as the product owner starts to see the product learning more about the software product while the developers are also learning more about the business. This allows the customer to drive the product according to the real needs he has at a certain time. It is important however to get as many features in the backlog at first, enough for the product owner to be able to prioritize the work and for the developers to develop in the first monthly iteration called sprint.
Projects are developed in SCRUM, using one month iterations called sprints. At the end of each sprint a potentially shippable product is delivered and presented to the product owner. Then another sprint is planned, built and delivered in the next 30 days and so on until the project is finished.
Each sprint starts with a sprint planning meeting where all the parties involved (the program owner, developers and SCRUM master) participate, but other interested parties like management or customer representatives can also be present. A meeting like this usually lasts up to an entire day, and is divided into two parts.
Part one of the planning meeting is when the product owner describes the most valuable items from the remaining features in the product backlog. This is done so that the features are described in more detail, so that later they can be estimated easier by the development team. When the team has something to clear up, this is done trough questions and direct conversations with the product owner. Not all remaining features are important to be described here by the customer, but enough from the product backlog, that can possibly fit in this sprint, choosing the most valuable first. The remaining items will be discussed in the future sprint planning meetings.
Trough this activity, the team and the product owner define where they want to get to when this sprint will be finished. Mike Cohn refers to this as defining the sprint goal. This is the expected and will be compared at the end of the iteration with the actual.
Part two of the sprint planning meeting is done to let the team see how much from the product backlog can they built in this sprint. For this the team discusses what they heard separately, seeing how much effort each item will need and seeing how many items fit into this sprint. Since the product backlog is sorted, by the product owner, descending on the basis of priority, the team can draw a line under the last item that can be included in the sprint. All these items will now be moved to the sprint backlog, in order to be built having the product owner approve the list. In some cases this list can be negotiated as some of the items might be more costly (in time) than others and based on this the product owner can reprioritize what needs to be done.
After the product backlog items are added to the sprint backlog, this list is sealed. Only in exceptional cases can it be modified, or items added to it, but this only with the explicit accept from the team.
The sprint backlog is different from the product backlog as in the sprint backlog, after the items have been moved from the product backlog, the sprint backlog items can be divided into programming tasks that are also items. The product backlog needs to be understood by the customer, but the sprint backlog can and should include tasks that can be understood only by the programmers and that help organize their work better.
Daily SCRUM meetings
At the beginning of each day, the team gets together for 15-30 minutes, to discuss the status of the project. This meeting goal cannot be derailed in any way, and is usually held with everyone standing in a circle, with each team member being asked the following questions by the SCRUM master:
- What did you do yesterday?
- What will you do until the tomorrow daily SCRUM?
- What prevents you from doing your work?
The daily meeting’s main purpose is for all to know where the project stands and for each to commit to something in front of the others, not the SCRUM master. The SCRUM master needs to do whatever possible to eliminate the obstacles raised by the answers to the 3rd question.
The daily meetings can be attended by other stake holders such as managers, even CEO to see progress; however they are not allowed to speak, just to hear. This is also known as the “pigs and chicken” technique, with the team being the pigs and the management being the chickens, being inspired from a short very relevant story:
A pig and a chicken discussed the name of their new restaurant. The chicken suggested Ham n' Eggs. "No thanks," said the pig, "I'd be committed, but you'd only be involved!"
[Larman, 2005]
Developing
SCRUM does not impose strict engineering practices like XP does, but it emphasizes the need for quality work, automated tests and daily builds of the system. Many teams do use TDD, Continuous Integration, even user stories and other practices from XP with great success, having a mixture of agile methodologies, as these agile methodologies have evolved together, XP planning game being influenced by SCRUM, and developing very successful projects that way.
Product presentation meeting or sprint review meeting
When a sprint has been finished (at the end of the 30 days) a sprint review meeting is held to compare the expected with the actual built, together with the entire team, the SCRUM master, the product owner being present and other stake holders. The meeting is very informal and PowerPoint slides and presentations are strictly being prohibited, the focus being on showing progress, by showing the software, going trough all newly developed backlog items from this sprint. After all, what better way to show progress than the product itself?
An emphasis is also put on getting feedback after seeing the product demo. Craig Larman says:
Feedback and brainstorming on future directions is encouraged, but no commitments are made during the meeting. Later at the next Sprint Planning meeting, stakeholders and the team make commitments
[Larman, 2005]
Doing it all over again
After the sprint has been finished and the actual result presented to the product owner and the other interested parties, it is time to take things from the beginning with the next sprint starting with the sprint planning meeting. This is done over and over again until the customer considers that the product is finished.

Scaling SCRUM
Usually a SCRUM team consists of four to seven team members. This does raise the question of how does SCRUM work when more then 7 developers are needed. The answer is in having more SCRUM teams, with daily meetings also being held across teams, each team sending a representative to these meetings.
Projects with several hundred developers have been developed using SCRUM, from small projects to large multi country teams with 330 to 600 developers involved, as the IDX project [Larman, 2005], [Cohn, 2004].
SCRUM is a project management method that exceeds the borders of software development being used in other domains as well. It is a “simple process for managing complex projects” in general, very well suited for software.
2.6 Crystal Clear
Introduction
Since 1990, methodology anthropologist Alistair Cockburn has studied all over the world how successful teams of developers build and deliver software, over and over again, and listed his findings in a methodology family called Crystal, which is composed of more methodologies, divided by the size of the team and also by the importance of the project, varying from the lightest: Crystal Clear to heavier methodologies, that get darker colors, such as yellow, Orange, Red etc, having the author believe that heavier processes are needed for larger projects, starting from the concept that one methodology cannot cover all aspects of software development.
What is Crystal Clear?
CC aims to be a simple and tolerant set of rules that puts the project on the safety zone. It is, if you will, the least methodology that could possibly work, because it shows much tolerance (Cockburn, 2005)
How do Crystal Clear teams work?
Properties, Tools and Practices
CC is based on a set of seven properties, which deeply influence development: frequent delivery, reflective improvement and close communication, personal safety, focus, early access to expert users and technical environment with automated tests, configuration management and frequent integration, but only the first 3 are a must.
Following CC the developers are organized in teams consisting of 2-8 members, with at least one level 3 developer, usually sitting in the same room, facing each other in order to facilitate verbal communication as much as possible. They sit side by side and collaborate often, this technique being called side-by-side programming. This is very similar with XP’s pair programming but differs from it as each team member has his own computer and can develop alone, or with the colleague on the right or on the left.
The development is divided into periods lasting from 1-4 months called deliveries, at the end of which the software will be deployed to the end users. Between these deliveries, at regular intervals, called iterations, the customer representatives are shown the working product and the feedback from them is gathered.
Requirements are obtained from the customer as “light” use cases and are obtained and prioritized together, with the customer and then a delivery plan is built for the next delivery.
CC teams constantly look back and improve the way they are working, both at the end of the iteration but also in the middle of it. This technique is put in practice by dividing actions done in 3 lists: things that worked and should be kept, things that didn’t work and should be dropped and things that could be tried next.
The design activity, which is continuous throughout the project, is done on a whiteboard, and if there’s need to keep a record of it, it is photographed and included into a document straight from the whiteboard.
The code being written is deliberately architected so that it can support a fully regression automated testing suite. These regression tests give them the possibility to do lots of changes and to adapt easily to shifts in direction of the product being developed, but the coding style is in the hand of the developers, they being the one that decide what best suites them. There are also as many integrations as possible putting together all the parts of the system and running the whole regression suite of tests.
Any team member can feel safe always telling what he thinks, like telling a manager that a schedule is unrealistic or a colleague that his design needs rework. Alistair Cockburn calls this the first step toward trust.
CC teams always focus on what’s the most important thing that needs to be taken care of now, and always have easy access to expert users or the client, that can always be asked to clear misunderstandings, to plan the next deliverable product or to receive feedback from them.
Besides the 7 properties of CC, it also comes with a series of recommended strategies and techniques, to be able to deliver value to the client fast. Some of them are very similar, inspired from or have evolved with practices from other agile methodologies.
There are 4 strategies: exploratory 360, walking skeleton, incremental rearchitecture and information radiators and 9 techniques: methodology shaping, reflection workshop, blitz planning, Delphi estimation using expertise rankings, daily stand up meetings, essential interaction design, process miniature, side by side programming and burn charts.
2.7 Lean Software Development
Lean software development is not a day to day strict practice methodology, but rather a set of 7 principles and 22 tools that can be used to successfully manage a project. Lean software development comes to complete the practices from other agile methodologies, with lessons learned in other industries, that are more advanced and mature that the software development branch. Jim Highsmith, said about lean software development that it presents a toolkit for project managers, team leaders, and technology managers who want to add value rather then become roadblocks to their project teams.
Origins
Much before the software industry, the auto industry had given up the waterfall model, in favor of a more lightweight but efficient model, that can produce results faster and in a concurrent manner. Mary and Tom Poppendieck published “Lean Software Development: An Agile Toolkit” in 2003,doing a wonderful job in adapting the lean principles, used in manufacturing, to software development. They have proved these practices, developing and managing software projects, demonstrating that not the inspiration from another industry was bad (some advocates of the agile methodologies have claimed that the inspiration in the 60-70’s from mechanical and construction engineering caused many problems in software), but that the mistake was not evolving with manufacturing and other industries when they dropped the waterfall model.
Mary and Tom also showed that some of the previous attempts to adapt lean principles to software failed because they were started wrong, without realizing the difference between development and product manufacturing.
The 7 principles
Eliminate waste – Taiichi Ohno’s (the father of Toyota Production System) said that anything that does not add value to a product, as perceived by the customer is waste. All agile methodologies have emerged as a response to chaos where the amount of wrongly used resources generates lots of overhead and waste , thus having a method to identify and cut unproductive activities, is considered, for software development as well, a very important tool.
In software development, the following are considered waste: partially done work, extra processes, extra features (never needed or used), task switching (people learning one system, then moving to another where another learning curve is needed), waiting, motion and defects.
Value stream mapping is the chart that enables you to simply see the periods that add value and the periods where time is wasted. Put in practice, this is a tremendous tool, showing huge gaps between value and waste.

[Value stream mapping in traditional processes, from “Lean Software Development: An Agile Toolkit”]
Amplify learning
Software development is a continuous learning and adapting activity between the customer and the developers, which learn from each other, communicate better and thus build better and more useful software. Feedback (tool 3) amplifies the learning process and because it is based
Synchronization (tool 5) allows concurrent development. Good synchronization is achieved with the customer through iterations (tool 4) and with the colleagues mostly with frequent code integration and reverse testing sessions. Synchronization is achieved better if we start from the interaction point first, from the interfaces of the different components.
Set based development (tool 6) is one of the greatest lessons we can learn about communication. Saying what the constrains of a system that needs to be built are allows the developer of the system to come up with more choices, with a set of solutions. Combined with further requirements, from that set of solutions the one that passes all constrains will emerge. If we ask specifically for a choice we might miss several alternatives and find ourselves stuck.
Decide as late as possible
Deciding for the future has been proved wrong as it can never predict changes and makes the cost of change enormous. Deciding later based on more information and keeping your options open (Options thinking – tool 7) is a better option. The last responsible moment (tool 8) enables you to take responsible decisions (making decisions – tool 9) late but not too late.
Deliver as fast as possible
Until recently rapid software development has not been valued; taking a careful, don’t make any mistakes approach has seemed to be more important
[Poppendieck and Poppendieck, 2003]
Lean product manufacturing and agile software development have proved that fast delivery is possible and leads to more satisfactory results for the customer. Recommended tools inspired from lean manufacturing are: Pull systems (tool 10), queuing theory (tool 11) and cost of change (tool 12)
Empower the team
Highly motivated, self organized teams, that have power to take decisions and put their ideas into practice, being lead by people with expertise, have always been a recipe for success (Self determination (tool 13), Motivation (tool 14), Leadership (tool 15), Expertise (tool 16))
Build integrity in
Perceived and conceptual integrity is what we understand by external and internal quality of a software product. If the integrity (tool 17) perceived by the customer is good, then the software that was asked for was built and is of high quality, and if the conceptual quality (tool 18) is goof, then the product’s internal quality is good, meaning that it can be extended, maintained and kept longer in use. The two fundamental practices at the base of integrity are testing (tool 20) and refactoring (tool 19).
See the whole
Making parts of a whole, at the highest quality does not necessary mean that when they are assembled together, the resulting system is at the highest quality and as required. Focusing on the whole system, helps making the parts better suited to work with each other and to compose a better system. The tools mentioned in achieving these are: Measurements (tool 21) and Contracts (tool 22)
Lean software development principles and tools should be in every agilist’s pocket no matter what methodology they follow, as they represent invaluable advice and proven practices to enhance efficiency.
2.8 AMDD – Agile Model Driven Development
AMDD is a light-weight approach for enhancing modeling and documentation efforts for other agile software processes such as XP and RUP [Ambler 2005], being extremely valuable in situations where written documentation and modeling are required. It is based on a set of principles, values and practices, which explain and enhance the role of modeling and documentation, in agile methodologies, based on the sufficiency principle, leaving unnecessary detail out.

Its author, Scott Ambler, a very active member of the agile community with great contributions especially on agile modeling, agile databases and database refactoring techniques, emphasizes in AMDD, that all agile methodologies include modeling, from the simple user stories and CRC cards to the automated tests as primary artifacts: acceptance tests as primary artifacts for requirements and unit tests as detailed design artifacts.
2.9 DSDM – Dynamic Systems Development Method
DSDM is an agile methodology, developed since 1994, and continuously improved by a non profit organization, called the DSDM consortium.
DSDM, breaks from traditional software methodologies, looking the work, from an entire different perspective:

DSDM is based on the following as core concepts: active user involvement, team empowered to make decisions, frequent releases, iterative development that are user feedback driven, reversible changes, requirements defined early at a high level, integrated testing, essential communication and collaboration, 20%/80% rule and having the goal to fit the business purpose.
2.10 FDD – Feature Driven Development
FDD is an agile methodology, developed by Jeff DeLuca and Peter Code, since around 1997, that puts bigger emphasize on modeling and offers good predictability in projects with more stable requirements, consisting of two main stages: discovering the features to implement and implementing them one by one.
The first stage, discovering the features, is done with the customers on site and marks the features to be implementing using UML.
The second stage develops the features, in 1-3 week iterations, in which more features to be done, are packaged. At the end of each iteration, the software produced is considered shippable.
2.11 Adaptive Software Development
Jim Highsmith is one of the most respected book authors and lightweight methodology advocates, in the agile community. He wrote a series of books on agile software development and agile software management, defining the Adaptive methodology, where he promotes the need for the continuous evolution and adaptation of the process used. He states that software development should be developed incrementally and iterative, trough repetitive cycles that include 3 stages: speculate, collaborate and learn.































